第一章 · 基本概念
-
状态 state:在环境中所处的状态,包括位置、速度、加速度等。 -
状态空间 state space:状态空间,表示所有状态的集合 -
动作 Action:动作,对于一个state有上下左右和静止五种状态。 -
动作空间 Action space:动作空间,每个状态单独拥有一个状态空间,包含五种状态。 $$ A(s) = { a \in A \mid a \text{ 在状态 } s \text{ 可行} } $$ -
状态转移 state transition:state 通过 action后,状态转变。 -
策略 policy:智能体应该采取什么action来到达target cell。以下用pi来代表策略的条件概率,比如在下图中,s1要到达target,根据箭头只能采取a2,所以a2概率为1,其他为0。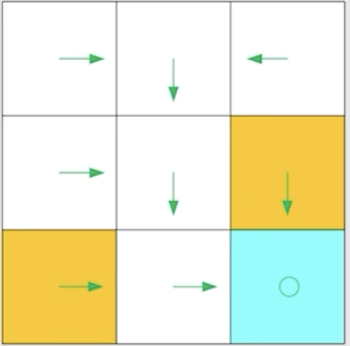
策略图
奖励Reward
Reward:奖励值,有正负之分,通常来说正值代表鼓励encouragement,负值代表惩罚punishment。正的奖励表示我们鼓励智能体采取相应的动作;负的奖励表示我们不鼓励智能体采取该动作。即时奖励 immediate reward:采取一个动作后可以立即得到的奖励。从长远来看,即时奖励越大不代表越好。总奖励 total reward:总任务的最终奖励。- 使用条件概率来描述更加一般化的奖励过程,如果s1采取a1得到的reward为-1,则数学表示为
$$ P(r = -1 \mid s1,a1) = 1 $$ $$ P(r \neq -1 \mid s1,a1) = 0 $$
轨迹、回报、回合
-
轨迹 trajectory:从start state 到达 target state的一条路径,即状态转换链。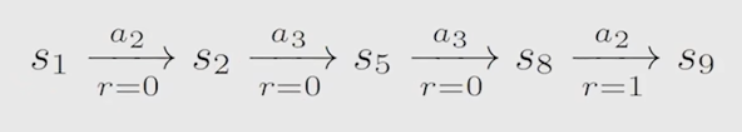
轨迹图 -
回报 return:沿着trajectory计算reward的总和。作为评判trajectory好坏的标准。回报也可以称为总奖励。回报由即时奖励和未来奖励组成。 -
当agent到达target cell后,会一直在target位置执行action,而此时reward一直为1,所以return持续加1,变为无穷值。
-
折扣因子 discount rate:为了解决这个问题,引入了γ-折扣因子,使用以下公式计算折扣回报 discount return。$$ G_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \gamma^3 r_{t+3} + \dots = \sum_{k=0}^{\infty} \gamma^k r_{t+k} $$
由于γ在[0,1),所以随着return的不断增加,reward所占的权重越来越小。同时,还可以使用γ来平衡更远或者更近的rewards。越接近0,长远的γ多次方就会更小,于是就跟注重短时;越接近1,长远的γ就会偏大,更注重长远。
为什么不从第一项开始加discount rate?
个人认为,r_t是下一时刻马上就能获得的奖励,是确定的,所以不用加discount rate。而为了逐渐减少未来奖励的重要性,从第二项开始乘上系数。
-
回合 episode:一般指一段有限的trajectory,如果一个任务最多是有限多步,那么被称为“回合制任务”,否则为“持续性任务”。我们可以在回合制任务到达终止状态后将其转变为持续性任务 -
终止状态 terminal states:这条有终止状态的trajectory称为一个episode
马尔可夫决策过程
马尔可夫性 Markov property:下一状态的概率分布,只取决于当前状态,即无记忆性。
$$ P(s_{t+1} \mid s_t, a_t, s_{t-1}, a_{t-1}, \dots, s0, a0) = P(s_{t+1} \mid s_t, a_t) $$ $$ P(r_{r+1} \mid s_t, a_t, s_{t-1}, a_{t-1}, \dots, s0, a0) = P(r_{t+1} \mid s_t, a_t) $$
其中,t表示当前时刻,t+1表示下一个时刻。以上两个公式表明,下一时刻的状态转移概率和奖励概率,仅仅取决于当前时刻的状态和动作,与之前的一系列状态动作无关。这就是马尔可夫性质中无记忆性的体现。
马尔可夫过程(Markov Process, MP):马尔可夫过程是一种随机过程,它满足马尔可夫性。当前状态已经包含了所有对未来的影响,过去的状态在给定当前状态后不再影响未来。
马尔可夫决策过程(Markov Decision Process, MDP)是在马尔可夫过程的基础上,引入了动作和奖励两个元素,用来描述智能体在环境中进行决策与反馈的过程。通常定义为五元组:
$$ \text{MDP} = \langle \mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R}, \gamma \rangle $$
问题:马尔可夫决策过程与马尔可夫过程的区别?
主要区别在于是否存在“决策”。
在 MDP 中,智能体在每个状态下可以根据策略选择不同的动作,不同的动作会导致不同的状态转移和奖励;而 MP 只描述系统的状态转移规律,没有动作和奖励的概念,也不存在决策过程。
当一个 MDP 的策略被确定下来后,动作的选择就不再具有随机决策意义,状态转移概率由策略完全确定,因此此时 MDP 退化为一个马尔可夫过程(更准确地说,是马尔可夫奖励过程 MRP)。