强化学习的数学原理–第二章
上一章提到,return十分重要,因为可以用其评估某条线路的好坏。简单来说,return可以通过定义进行计算,即沿着路线依次将reward相加;另外,回报也可以通过自举法(bootstrapping)求出。
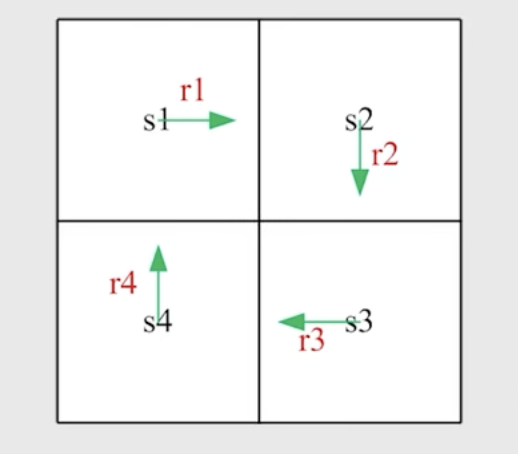
-
定义法:沿着路线依次将reward相加。
$$ v_1 = r_{1} + \gamma r_{2} + \gamma^2 r_{3} + \gamma^3 r_{4} $$
$$ v_2 = r_{2} + \gamma r_{3} + \gamma^2 r_{4} + \gamma^3 r_{1} $$
$$ v_3 = r_{3} + \gamma r_{4} + \gamma^2 r_{1} + \gamma^3 r_{2} $$
$$ v_4 = r_{4} + \gamma r_{1} + \gamma^2 r_{2} + \gamma^3 r_{3} $$
-
自举法:我们可以观察大,每一个vi都可以提出一个vj,例如
$$ v_1 = r_1 + \gamma(r_2 + \gamma r_3 + \cdots) = r_1 + \gamma v_2 $$
这是一个有趣的现象,从不同状态出发的回报值是彼此依赖的,这也是贝尔曼方程的核心思想。如果我们将其整理为矩阵-向量的线性方程形式:
$$ \begin{bmatrix} v_1 \newline v_2 \newline v_3 \newline v_4 \end{bmatrix}= \begin{bmatrix} r_1 \newline r_2 \newline r_3 \newline r_4 \end{bmatrix}+ \begin{bmatrix} \gamma v_2 \newline \gamma v_3 \newline \gamma v_4 \newline \gamma v_1 \end{bmatrix}= \begin{bmatrix} r_1 \newline r_2 \newline r_3 \newline r_4 \end{bmatrix}+ \gamma \begin{bmatrix} 0 & 1 & 0 & 0 \newline 0 & 0 & 1 & 0 \newline 0 & 0 & 0 & 1 \newline 1 & 0 & 0 & 0 \end{bmatrix} \begin{bmatrix} v_1 \newline v_2 \newline v_3 \newline v_4 \end{bmatrix} $$
可以简写为以下形式,移项求逆就可以求出v。 $$ v = r + \gamma Pv $$
状态值 state value
回报 return是对于单个轨迹确定的,然而通常情况下一个状态出发可能会得到不同的轨迹和回报。所以,我们需要引入状态值的概念。状态值也就是平均值、期望,状态值越高说明这条轨迹效果越好。
按照之前的定义折扣回报为:
$$ G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots $$
这里的Gt是一个随机变量,所以我们可以计算它的期望值。
$$
v_\pi(S) = \mathbb{E}[G_t \mid S_t= s]
$$
也就是,在状态为s的情况下,回报的平均值为$v_\pi(S)$,它也被称为状态值函数,或者状态值 state value。这里注意三点:
- $v_\pi(S)$的值依赖于$s$,因为不同的状态的状态值一般是不同的。
- $v_\pi(S)$的值依赖于$\pi$,也就是策略,因为不同的策略会导致不同的动作从而使状态值不同。
- $v_\pi(S)$的值不依赖于$t$,因为系统是稳定的,不会因为你的出发时间而变化。
状态值与回报的关系是什么?
当轨迹确定时,会得到一个确定的回报。如果轨迹不确定或者说有多条轨迹时,通过概率算出的回报期望就是状态值。
贝尔曼方程
公式推导
由上文可得 $$ v_\pi(s) = \mathbb{E}[G_t \mid S_t= s] $$ 其中 $$ G_t = R_{t} + \gamma R_{t+1} + \gamma^2 R_{t+2} + \dots = R_t + \gamma G_{t+1} $$ 所以 $$ \begin{align*} v_\pi(s) &= \mathbb{E} \big[ G_t \mid S_t = s \big] \newline &= \mathbb{E} \big[ R_t + \gamma G_{t+1} \mid S_t = s \big] \newline &= \mathbb{E} \big[ R_t \mid S_t = s \big] + \gamma \mathbb{E} \big[G_{t+1} \mid S_t = s \big] \end{align*} $$ 分别计算两项:
$$ \begin{align*} \mathbb{E}[R_t \mid S_t = s] &= \sum_a \pi(a|s) \mathbb{E}[R_t \mid S_t = s, A_t = a] \newline &= \sum_a \pi(a|s) \sum_a p(r|s,a)r \end{align*} $$
解释:状态$s$下的回报期望为,执行$a$动作的概率,乘上执行$a$动作的奖励期望。同理,奖励期望由可以拆解为,$s$状态下执行$a$动作获得该奖励的概率,乘上奖励值。
$$ \begin{align*} \mathbb{E} \big[G_{t+1} \mid S_t = s \big] &= p(s_{t+1}|s) \sum_s\mathbb{E} \big[G_{t+1} \mid S_{t+1} = s_{t+1} \big] \newline &= p(s_{t+1}|s) \sum_sv_\pi(s_{t+1}) \newline &= \sum_a \pi(a|s) p(s_{t+1}|s,a) \sum_sv_\pi(s_{t+1}) \end{align*} $$
解释:要求状态$s$下的$G_{t+1}$,$s$跳到$s_{t+1}$的概率乘上在$s_{t+1}$状态下的状态值。而$s$跳到$s_{t+1}$的概率可以拆解为执行动作$a$的概率乘上执行完动作$a$跳到$s_{t+1}$的概率。
再将两项加起来提出一个共同项: $$ v_\pi(s) = \sum_a \pi(a|s) \sum_a p(r|s,a)r + \gamma \sum_a \pi(a|s)p(s_{t+1}|s,a) v_\pi(s_{t+1}) \newline $$ 得到贝尔曼方程 $$ v_\pi(s) = \sum_a \pi(a|s) \left[ \sum_r p(r|s,a) r + \gamma \sum_{s’} p(s_{t+1}|s,a) v_\pi(s_{t+1}) \right] $$
如何理解这个等式呢?贝尔曼方程的本质在于从$s$出发的回报,等于即时奖励加上下一个状态出发的回报。
矩阵向量形式
由于每一个$v_\pi(s)$都可以得到$v_\pi(s_{t+1})$的方程,所以我们可以联立这些方程进而得到简洁的矩阵-向量形式。
首先我们将上述贝尔曼公式重写为: $$ v_\pi(s) = r_\pi(s) + \gamma \sum_s p_\pi(s’ \mid s)v_\pi(s’) $$ 这里$r_\pi(s)$表示即时奖励的期望值,而$p_\pi(s’ \mid s)$代表在策略$\pi$下从状态$s$经过一步转移到状态$s’$的概率。写成矩阵向量形式如下: $$ v_\pi = r_\pi + \gamma P_\pi v_\pi $$ 例子:当环境中有四个状态时,矩阵形式如下。 $$ \begin{bmatrix} v_{\pi}(s_1) \newline v_{\pi}(s_2) \newline v_{\pi}(s_3) \newline v_{\pi}(s_4) \end{bmatrix}= \begin{bmatrix} r_{\pi}(s_1) \newline r_{\pi}(s_2) \newline r_{\pi}(s_3) \newline r_{\pi}(s_4) \end{bmatrix} + \gamma \begin{bmatrix} p_{\pi}(s_1|s_1) & p_{\pi}(s_2|s_1) & p_{\pi}(s_3|s_1) & p_{\pi}(s_4|s_1) \newline p_{\pi}(s_1|s_2) & p_{\pi}(s_2|s_2) & p_{\pi}(s_3|s_2) & p_{\pi}(s_4|s_2) \newline p_{\pi}(s_1|s_3) & p_{\pi}(s_2|s_3) & p_{\pi}(s_3|s_3) & p_{\pi}(s_4|s_3) \newline p_{\pi}(s_1|s_4) & p_{\pi}(s_2|s_4) & p_{\pi}(s_3|s_4) & p_{\pi}(s_4|s_4) \end{bmatrix} \begin{bmatrix} v_{\pi}(s_1) \newline v_{\pi}(s_2) \newline v_{\pi}(s_3) \newline v_{\pi}(s_4) \end{bmatrix} $$
动作值 action value
动作值定义为:在一个状态采取一个动作之后获得的回报的期望值。 $$ q_\pi(s,a) = \mathbb{E} \big[ G_t \mid S_t = s, A_t = a \big] $$ 动作值依赖于一个状态-动作配对,而不是单单一个动作。
动作值和状态值的关系如下: $$ v_\pi(s) = \sum_a \pi(a|s) q_\pi(s,a) $$ 由上式可以看出,状态值是该状态对应的动作值的期望值。
此外,又因为(13)式,我们可以得到: $$ q_\pi(s,a) = \sum_r p(r|s,a) r + \gamma \sum_{s’} p(s_{t+1}|s,a) v_\pi(s_{t+1}) $$ 可见,动作值是一个包含状态值的变量的期望值。