值迭代算法(value iteration)
由上一章可知 $$ v_{k+1} = \max_{\pi \in \Pi} (r_{\pi} + \gamma P_\pi v_k) $$ 当 $k \to \infty$ 时,$v_k$ 以指数速度收敛到$v^*$。
值迭代算法包括两个步骤:
-
策略更新:根据上一步计算出的估计值向量,求解出最好的策略。 $$ \pi ^ * = \arg\max_{\pi \in \Pi} (r_\pi + \gamma P_\pi v^* ) $$
-
值更新:在得到当前最好策略之后,通过以下式子计算新的估计值向量。 $$ v_{k+1} = r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}}v_k $$ 之后反复进行迭代,直到 $v_k$ 收敛,例如 $||v_{k+1} - v_{k}||$ 小于一个很小的数。
为什么称 $v_k$ 为估计值向量而不是状态值?
状态值的定义是:从某个状态出发的期望回报等于立即奖励 + 折扣后的下一状态期望回报。这也表明必须要满足: $$ v_\pi = r_\pi + \gamma P_\pi v_\pi $$ 的 $v_\pi$ 才能被称为状态值,上面的 $v_k$ 和 $v_{k+1}$ 都是迭代中的中间值,而最终迭代完成的值才是状态值。
算法流程如图所示:

下面用一个简单的例子详细的描述该算法的原理。
已知 $r_{boundary} = r_{forbidden} = −1 $ , $r_{target} = 1$ 。黄色为禁行区域,蓝色为目标区域。
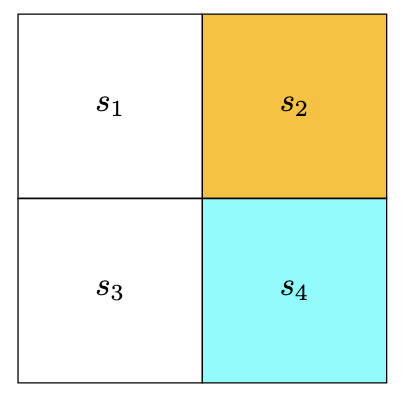
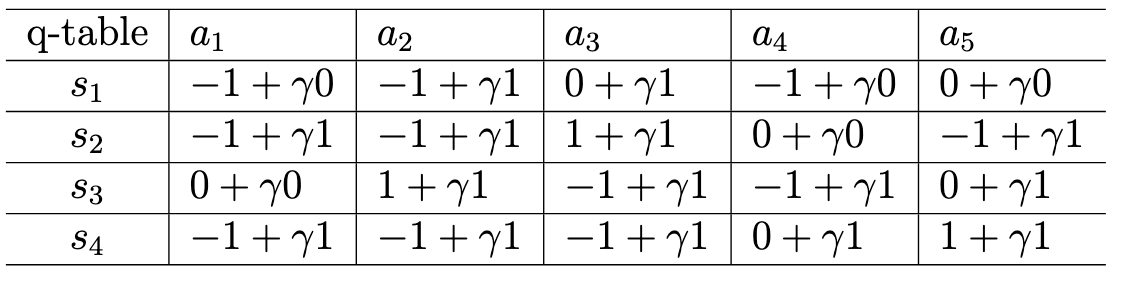
初始值 $v_0$ 可以任意选择,这里选择为 $v_0 (s_1) = v_0 (s_2) = v_0 (s_3) = v_0 (s_4) = 0$ ,我们可以建立一个q-table:

注意往上方移动为 $a_1$,按顺时针方向为$a_1、$a_2$、$a_3$。将 $v_0$都代入公式后,得到如下的表:
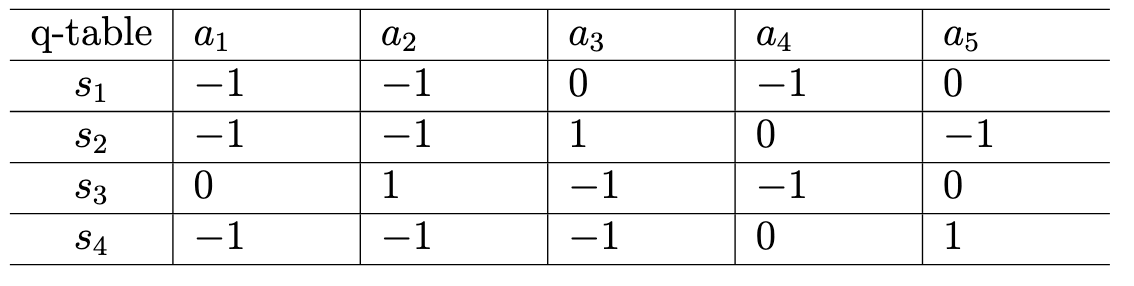
可以对每个状态选出动作值最大的动作,作为更新的策略。由于这里s1无论是原地不动还是进入s3,它所获得的奖励都是0,所以随机选取了一个最好策略为原地不动。
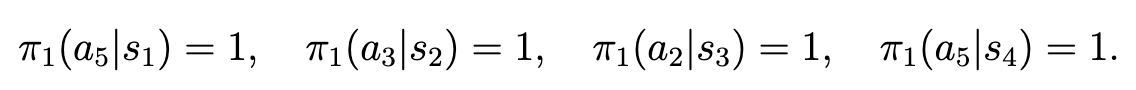
然后将每个状态下最大的动作值作为值更新。
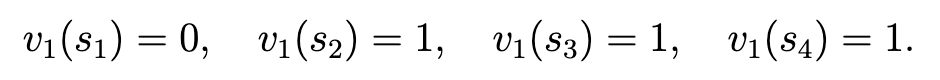
这里的 $v_1 (S_1) = 0$ 表示从 $S_1$ 出发的最好回报为0。
可以得到目前的策略为:
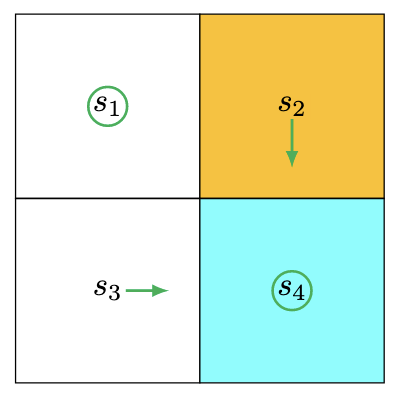
接着继续进行迭代:
解释一下这里的 $(s_2, a_2)$ 是如何计算的。
首先我们知道,值更新 = 立即奖励 + 折扣后的下一状态期望回报。
从 $s_1$ 出发执行 $a_2$ 会进入 $s_2$,其立即奖励为-1;到达 $s_2$ 之后,已知从 $s_2$ 出发的最好回报为1,再所以加上折扣*1。
计算完成并进行策略更新后得到的策略如下图:
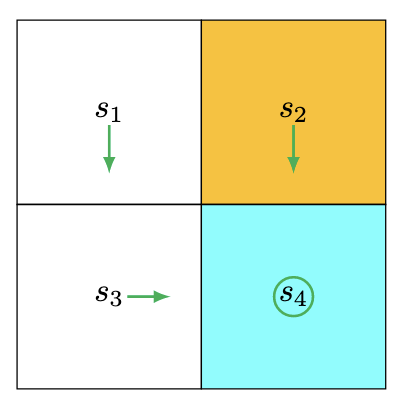
我们可以发现,原本s1是选择原地不动的,但是经过一次迭代之后它选择了往s3走。这是因为,在第二次迭代中s1如果还是选择原地不动,那么它的奖励仍然是0;但是如果选择向s3走,那么它会加上一个s3的最好回报,也就是奖励变为1。
我把这种迭代方式称为辐射迭代,因为这看起来像是先找靠近终点状态的最优策略,再逐渐扩散找到更远处状态的最优策略。
策略迭代算法(policy iteration)
策略迭代算法包括两个步骤:
-
策略评价:用于评估上一次迭代得到的策略。通过对状态估计值向量的多次迭代取收敛求解下面贝尔曼方程: $$ v_{\pi_k} = r_{\pi_{k}} + \gamma P_{\pi_{k}}v_{\pi_k} $$
-
策略改进:用上一步得到的状态值 $v_{\pi_k}$ 改进策略,得到更新的策略。 $$ \pi_{k+1} = \arg\max_{\pi \in \Pi} (r_\pi + \gamma P_\pi v_{\pi_k}) $$
迭代过程: $$ \pi_0 \xrightarrow{\text{评估}} v_{\pi_0} \xrightarrow{\text{改进}} \pi_1 \xrightarrow{\text{评估}} v_{\pi_1} \xrightarrow{\text{改进}} \pi_2 \xrightarrow{\text{评估}} \dots \xrightarrow{\text{改进}} \pi^* $$ 由于策略评价最终会收敛到最优状态值 $v^$,所以策略也会收敛到最优策略 $\pi^ $。
这种迭代方式也是先找到靠近target的最优策略,再向周围辐射。
值迭代与策略迭代的区别?
值迭代:在
值更新中计算出下一个估计值后,立刻用新的状态值反解策略(策略更新)。决定更新的是估计值,反解策略只是为了计算下一个估计值。它是在不断交替值更新和策略更新中得到收敛的。策略迭代:在单步中收敛出状态值,然后用这个状态值去更新出新的策略。此时,决定更新的是策略,收敛状态值只是为了求出更好的策略。此外,它是收敛后才更新的,每次更新中都要进行一次收敛。
总结一下,
值迭代算法是对每一次更新进行收敛,策略迭代是对每一次收敛进行更新。
截断策略迭代算法
根据上面讨论,可以知道值迭代算法在计算一次估计值后,马上进行策略更新:
$$
v_{k+1} = r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}}v_k
$$
而策略迭代算法是在收敛出状态值后,再进行策略更新:
$$
v_{\pi_k} = r_{\pi_{k}} + \gamma P_{\pi_{k}}v_{\pi_k}
$$
一个是只计算一次,一个是计算无穷次。这是两个极端,那是否可以取一个中间的策略呢?这就是截断策略迭代算法。
我们可以确定一个迭代次数 $j$,当估计值的迭代次数达到 $j$时,就直接进行策略更新。

实际上,策略迭代算法只在理论上可行,因为我们不可能将一个估计值真的迭代无穷次后再进行策略更新。所以,真正在实现的策略迭代算法,其实就是截断策略迭代算法。
下面给出三种迭代算法的收敛速度的示意图:
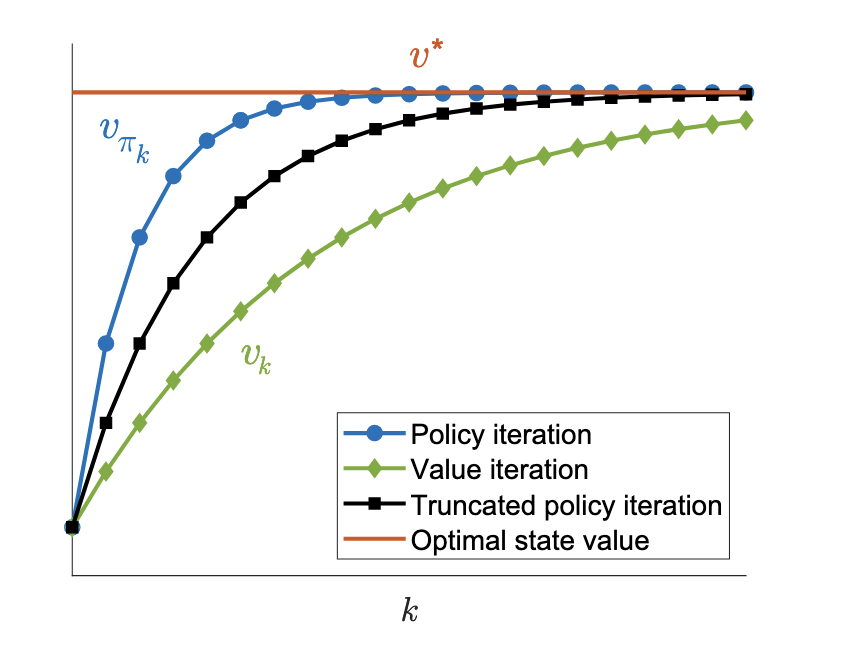
可以看出,策略迭代算法所需的迭代次数 $k$ 最少,值迭代算法所需的迭代次数最多,而截断策略迭代算法夹在中间。
注意:这并不意味着策略迭代就是最好最快的,因为此时横轴是迭代次数 $k$,而不是时间。虽然策略迭代的迭代次数少,但是它在每一次的迭代中都会执行无数次迭代直到收敛出状态值。所以其迭代时间不一定是最短的。
更多关于全国大学生智能汽车的分享,请访问个人主页。
期待你的评论与交流!