optimal policies
从直觉上来看,不同的policy会导致不同的return,而强化学习基本的思想就是找到一个最优策略optimal policies使得奖励最大。
如果对于任意的状态s,策略1的状态值都比策略2的状态值高。则称策略1优于策略二。
$$
v_{\pi_1}(s) \ge v_{\pi_2}(s), \quad \forall s \in S
$$
由此,给出最优策略和最优状态值的定义:
如果一项策略优于所有其他可能的策略,则该策略是最优的。并且该策略对应的状态值是最优状态值。
Bellman Optimality equation(BOE)
$$ \begin{align*} v(s) &= \max_{\pi(s) \in \Pi(s)} \sum_{a \in A} \pi(a|s) \left( \sum_{r \in R} p(r|s, a) r + \gamma \sum_{s’ \in S} p(s’|s, a) v(s’) \right) \newline &= \max_{\pi(s) \in \Pi(s)} \sum_{a \in A} \pi(a|s) q(s, a) \end{align*} $$
可以看出,贝尔曼最优公式就是在贝尔曼公式的基础上,增加了对策略的最大选择。此时,公式中有两个未知变量$v(s)$ 和 $\pi(a|s) $。你可能会面临以下问题:
- 该方程有解吗?
- 解是唯一的吗?
- 如何求解这个方程?
- 求出的解与最优策略有什么关系?
实际上,这两个变量可以一一求解。看如下这个例子: $$ x = \max_{y\in \R} (2x - 1 - y^2) $$ x和y都是未知量,问题就在于,如何取y,使得括号中的$(2x - 1 - y^2)$最大。显然,当y = 0时,括号中取的最大值$2x - 1$。这样就将y值确定了,然后再将y = 0代入,求得x = 1。
再来看贝尔曼最优公式: $$ v(s)= \max_{\pi(s) \in \Pi(s)} \sum_{a \in A} \pi(a|s) q(s, a) $$ 如何取策略$\pi$使得后面部分的求和最大呢?根据直觉来看,我们希望让$q(s,a)$越大的项乘上更大的权重$\pi(a|s)$。即最优策略应该选择具有最大动作值的动作,于是: $$ \pi(a|s) = \begin{cases} 1, & a = a^* \ 0, & a \ne a^* \end{cases} $$ 将上(3)式写为矩阵向量形式如下: $$ v= \max_{\pi \in \Pi}(r_\pi + \gamma P_\pi v) $$
压缩映射定理
压缩映射定理是分析非线性方程的强大工具,也被称为不动点定理。
-
不动点:考虑一个函数 $f(x)$ ,其中 $x \in \mathbb{R}$ 且 $f: \mathbb{R} \to \mathbb{R}$。如果一个点 \(x^*\) 满足:\[ f(x^*) = x^* \]那么这个点就叫不动点,因为 $x^*$ 的映射依然是自己。
-
压缩映射:如果存在 $\gamma \in (0,1)$ 使得对于任意的 $x1,x2$ 都满足: $$ ||f(x1) - f(x2)|| \le \gamma||x1 - x2|| $$ 那么函数 $f$ 被称为压缩映射。 -
压缩映射定理:对于方程 $x = f(x)$ ,如果 $f$ 是一个压缩映射,则下面所有性质都成立:- 存在性:一定存在一个不动点 $x$ 满足 $f(x) = x$;
- 唯一性:不动点 $x^*$ 是唯一的;
- 算法:考虑迭代算法 $x_{k+1} = f(x_k)$ ,给定任意一个初始值 $x_0$ ,当$k$趋近于无穷时,$x_k$ 趋近于 $x^*$ ,且具有指数收敛速度。
可以证明,贝尔曼最优方程右侧的函数$f(v)$是一个压缩映射,最优状态值和最优策略是存在且唯一的。
求解贝尔曼最优方程
如果$ v^* $是贝尔曼最优方程的解,那么它满足:
$$ v^* = f(v^*) = \max_{\pi \in \Pi} (r_{\pi} + \gamma P_\pi v^ *) $$
显然,$ v^* $是一个不动点,且是唯一最优解。可以通过如下迭代算法求解: $$ v_{k+1} = f(v_k) = \max_{\pi \in \Pi} (r_{\pi} + \gamma P_\pi v_k) $$ 当$k \to \infty$时,$v_k$以指数速度收敛到$v^*$。
求解最优策略$ \pi ^ * $: $$ \pi ^ * = \arg\max_{\pi \in \Pi} (r_\pi + \gamma P_\pi v^* ) $$ 最优状态值所对应的策略一定是最优策略,但是最优状态值唯一,最优策略却不唯一。因为多个策略可以产生同一个最优值函数。我们可以使用贪婪最优策略得到一个确定的最优策略: $$ \pi(a|s)= \begin{cases} 1,& a=a^*(s) \ 0,& \text{otherwise} \end{cases} $$ 注意:最优策略可以是随机的或者确定的,但是一定存在一个确定性的最优策略。
最优策略是随机的:比如如果多个动作并列第一,可以: $$ \pi(a_1|s)=0.7,\quad \pi(a_2|s)=0.3 $$ 这样依然是最优策略,但是是按概率随机选择的。
影响最优策略的因素
已知贝尔曼最优方程的元素展开形式是: $$ v(s) = \max_{\pi(s) \in \Pi(s)} \sum_{a \in A} \pi(a|s) \left( \sum_{r \in R} p(r|s, a) r + \gamma \sum_{s’ \in S} p(s’|s, a) v(s’) \right) $$ 在公式中,未知量$v$和$\pi$是有已知量决定的。当系统模型(即状态转移概率模型)确定时,最优策略会受到$r$和$\gamma$的影响。
下面讨论,当改变$r$和$\gamma$时,最优策略会如何变化。
折扣因子的影响
前文说到,折扣因子越小,越近视;折扣因子越大,越远视。
如下图情况,当$\gamma = 0.9$时,回报更远视,规划的路径可能会穿过障碍;而当$\gamma = 0.5$时,回报更近视,agent不再敢于冒险,反而选择更远的路径。
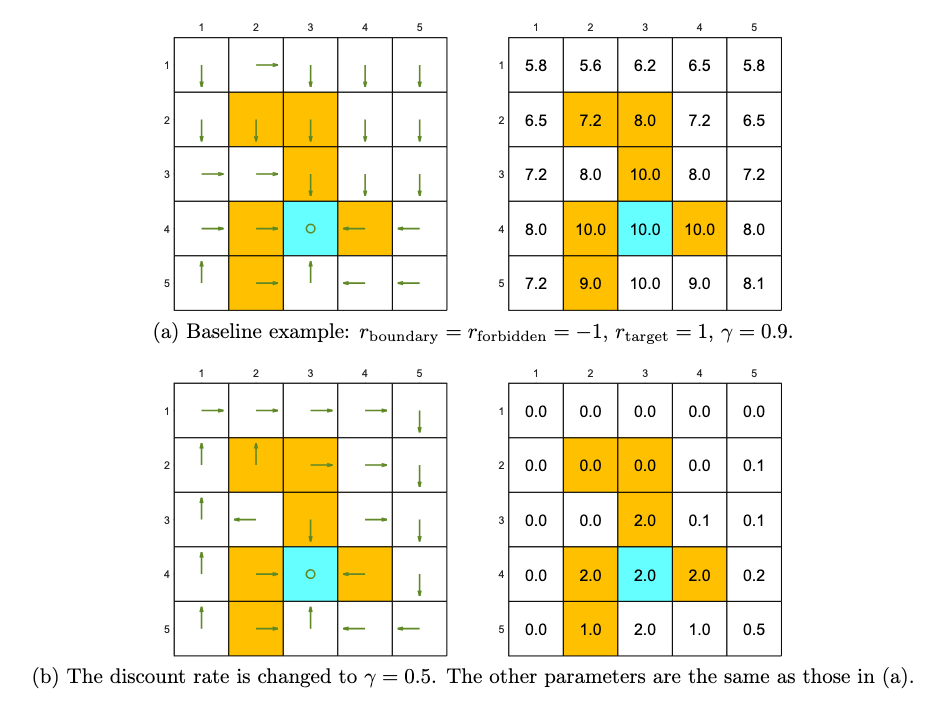
在极端状态下,$\gamma = 0$时,agent目光极其短浅,只会选择最大的即使奖励。
注意:为什么$\gamma = 0.9$时规划的路径会进入障碍?因为这个策略是“数学”上的最优策略,而不是“直觉”上的最优。想要让求出来的解更加贴合直觉最优,需要不断调整折扣因子或者奖励值来达到更好的效果。
奖励值的影响
可以调整奖励值的大小来改变最优策略,比如将障碍的奖励设置的非常低,那么最优策略就更能避开所有障碍。然而,如果对所有区域的奖励值进行线性缩放,则不会对最优策略产生影响。因为真正决定最优策略的不是回报的绝对值,而是不同策略所得回报之间的相对值。